Incorrect bounding box for characters #3511
Description
Environment
- Tesseract Version:
D:\Tesseract32>tesseract.exe --version
tesseract v5.0.0-alpha.20210506
leptonica-1.78.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0
Found AVX2
Found AVX
Found FMA
Found SSE4.1
Found libarchive 3.5.0 zlib/1.2.11 liblzma/5.2.3 bz2lib/1.0.6 liblz4/1.7.5 libzstd/1.4.5
Found libcurl/7.77.0-DEV Schannel zlib/1.2.11 zstd/1.4.5 libidn2/2.0.4 nghttp2/1.31.0
- Commit Number: I'm using Mannheim build
- Platform: Windows 10 64 bit, Tesseract compiled for 32 bit
Current Behavior:
Language: Russian + English.
I'm using CAPI and trying to get separate characters bounding boxes through iterator (TessPageIteratorBoundingBox(RIL_SYMBOL,...). For attached image I get correct characters for whole line but bounding boxes are wrong.
Line is «орешек).»
Up until second «е» character everything is great. I receive correct bounding boxes for «о», «р», «е» and «ш».
But this I get for second «е»:

This one for «к»:
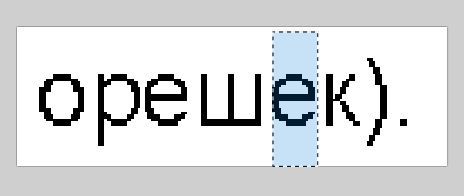
This for «)»:

And this for «.»:

Obviously bounding boxes are wrong.
Expected Behavior:
Proper bounding boxes.
Suggested Fix:
I'm not qualified enough.