A comprehensive ComfyUI integration for Microsoft's VibeVoice text-to-speech model, enabling high-quality single and multi-speaker voice synthesis directly within your ComfyUI workflows.
- 🎤 Single Speaker TTS: Generate natural speech with optional voice cloning
- 👥 Multi-Speaker Conversations: Support for up to 4 distinct speakers
- 🎯 Voice Cloning: Clone voices from audio samples
- 🎨 LoRA Support: Fine-tune voices with custom LoRA adapters (v1.4.0+)
- 🎚️ Voice Speed Control: Adjust speech rate by modifying reference voice speed (v1.5.0+)
- 📝 Text File Loading: Load scripts from text files
- 📚 Automatic Text Chunking: Handles long texts seamlessly with configurable chunk size
- ⏸️ Custom Pause Tags: Insert silences with
[pause]and[pause:ms]tags (wrapper feature) - 🔄 Node Chaining: Connect multiple VibeVoice nodes for complex workflows
- ⏹️ Interruption Support: Cancel operations before or between generations
- 🔧 Flexible Configuration: Control temperature, sampling, and guidance scale
- ⚡ Attention Mechanisms: Choose between auto, eager, sdpa, flash_attention_2 or sage
- 🎛️ Diffusion Steps: Adjustable quality vs speed trade-off (default: 20)
- 💾 Memory Management: Toggle automatic VRAM cleanup after generation
- 🧹 Free Memory Node: Manual memory control for complex workflows
- 🍎 Apple Silicon Support: Native GPU acceleration on M1/M2/M3 Macs via MPS
- 🔢 4-Bit Quantization: Reduced memory usage with minimal quality loss
- 📦 Self-Contained: Embedded VibeVoice code, no external dependencies
- 🔄 Universal Compatibility: Adaptive support for transformers v4.51.3+
- 🖥️ Cross-Platform: Works on Windows, Linux, and macOS
- 🎮 Multi-Backend: Supports CUDA, CPU, and MPS (Apple Silicon)
Click to watch the demo video
- Clone this repository into your ComfyUI custom nodes folder:
cd ComfyUI/custom_nodes
git clone https://github.com/Enemyx-net/VibeVoice-ComfyUI- Restart ComfyUI - the nodes will automatically install requirements on first use
Starting from version 1.6.0, models and tokenizer must be manually downloaded and placed in the correct folder. The wrapper no longer downloads them automatically.
You can download VibeVoice models from HuggingFace:
| Model | Size | Download Link |
|---|---|---|
| VibeVoice-1.5B | ~5GB | microsoft/VibeVoice-1.5B |
| VibeVoice-Large | ~17GB | aoi-ot/VibeVoice-Large |
| VibeVoice-Large-Quant-4Bit | ~7GB | DevParker/VibeVoice7b-low-vram |
VibeVoice uses the Qwen2.5-1.5B tokenizer:
- Download from: Qwen2.5-1.5B Tokenizer
- Required files:
tokenizer_config.json,vocab.json,merges.txt,tokenizer.json
-
Create the models folder if it doesn't exist:
ComfyUI/models/vibevoice/ -
Download and organize files in the vibevoice folder:
ComfyUI/models/vibevoice/ ├── tokenizer/ # Place Qwen tokenizer files here │ ├── tokenizer_config.json │ ├── vocab.json │ ├── merges.txt │ └── tokenizer.json ├── VibeVoice-1.5B/ # Model folder │ ├── config.json │ ├── model-00001-of-00003.safetensors │ ├── model-00002-of-00003.safetensors │ └── ... (other model files) ├── VibeVoice-Large/ │ └── ... (model files) └── my-custom-vibevoice/ # custom names are supported └── ... (model files) -
For models downloaded from HuggingFace using git-lfs or the HF CLI, you can also use the cache structure:
ComfyUI/models/vibevoice/ └── models--microsoft--VibeVoice-1.5B/ └── snapshots/ └── [hash]/ └── ... (model files) -
Refresh your browser - the models will appear in the dropdown menu
- The dropdown will show user-friendly names extracted from folder names
- Both regular folders and HuggingFace cache structures are supported
- Models are rescanned on every browser refresh
- Quantized models are automatically detected from their config files
- The tokenizer is searched in this priority order:
ComfyUI/models/vibevoice/tokenizer/(recommended)ComfyUI/models/vibevoice/models--Qwen--Qwen2.5-1.5B/(if exists from previous installations)- HuggingFace cache (if available)
Loads text content from files in ComfyUI's input/output/temp directories.
- Supported formats: .txt
- Output: Text string for TTS nodes
Generates speech from text using a single voice.
- Text Input: Direct text or connection from Load Text node
- Models: Select from available models in dropdown menu
- Voice Cloning: Optional audio input for voice cloning
- Parameters (in order):
text: Input text to convert to speechmodel: Select from dropdown list of available models found inComfyUI/models/vibevoice/attention_type: auto, eager, sdpa, flash_attention_2 or sage (default: auto)free_memory_after_generate: Free VRAM after generation (default: True)diffusion_steps: Number of denoising steps (5-100, default: 20)seed: Random seed for reproducibility (default: 42)cfg_scale: Classifier-free guidance (1.0-2.0, default: 1.3)use_sampling: Enable/disable deterministic generation (default: False)
- Optional Parameters:
voice_to_clone: Audio input for voice cloninglora: LoRA configuration from VibeVoice LoRA nodetemperature: Sampling temperature (0.1-2.0, default: 0.95)top_p: Nucleus sampling parameter (0.1-1.0, default: 0.95)max_words_per_chunk: Maximum words per chunk for long texts (100-500, default: 250)voice_speed_factor: Speech rate adjustment (0.8-1.2, default: 1.0, step: 0.01)
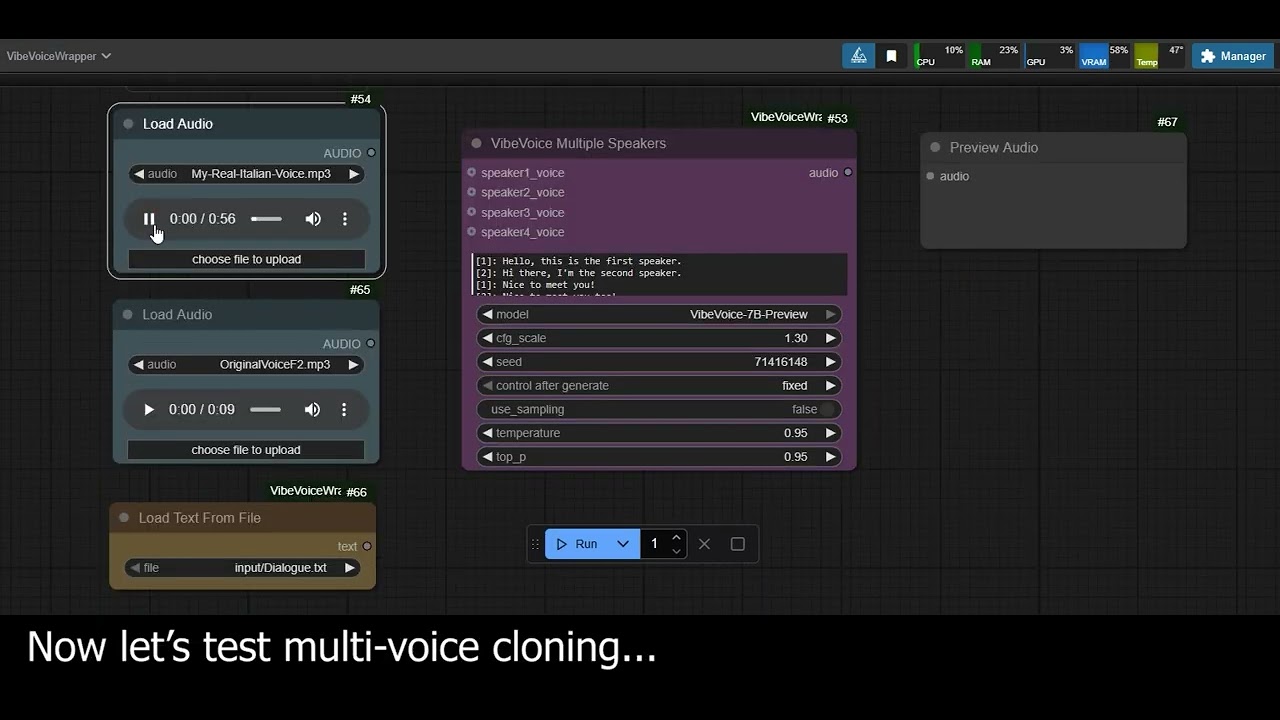
Generates multi-speaker conversations with distinct voices.
- Speaker Format: Use
[N]:notation where N is 1-4 - Voice Assignment: Optional voice samples for each speaker
- Recommended Model: VibeVoice-Large for better multi-speaker quality
- Parameters (in order):
text: Input text with speaker labelsmodel: Select from dropdown list of available models found inComfyUI/models/vibevoice/attention_type: auto, eager, sdpa, flash_attention_2 or sage (default: auto)free_memory_after_generate: Free VRAM after generation (default: True)diffusion_steps: Number of denoising steps (5-100, default: 20)seed: Random seed for reproducibility (default: 42)cfg_scale: Classifier-free guidance (1.0-2.0, default: 1.3)use_sampling: Enable/disable deterministic generation (default: False)
- Optional Parameters:
speaker1_voicetospeaker4_voice: Audio inputs for voice cloninglora: LoRA configuration from VibeVoice LoRA nodetemperature: Sampling temperature (0.1-2.0, default: 0.95)top_p: Nucleus sampling parameter (0.1-1.0, default: 0.95)voice_speed_factor: Speech rate adjustment for all speakers (0.8-1.2, default: 1.0, step: 0.01)
Manually frees all loaded VibeVoice models from memory.
- Input:
audio- Connect audio output to trigger memory cleanup - Output:
audio- Passes through the input audio unchanged - Use Case: Insert between nodes to free VRAM/RAM at specific workflow points
- Example:
[VibeVoice Node] → [Free Memory] → [Save Audio]
Configure and load custom LoRA adapters for fine-tuned VibeVoice models.
- LoRA Selection: Dropdown menu with available LoRA adapters
- LoRA Location: Place your LoRA folders in
ComfyUI/models/vibevoice/loras/ - Parameters:
lora_name: Select from available LoRA adapters or "None" to disablellm_strength: Strength of the language model LoRA (0.0-2.0, default: 1.0)use_llm: Apply language model LoRA component (default: True)use_diffusion_head: Apply diffusion head replacement (default: True)use_acoustic_connector: Apply acoustic connector LoRA (default: True)use_semantic_connector: Apply semantic connector LoRA (default: True)
- Output:
lora- LoRA configuration to connect to speaker nodes - Usage:
[VibeVoice LoRA] → [Single/Multiple Speaker Node]
For multi-speaker generation, format your text using the [N]: notation:
[1]: Hello, how are you today?
[2]: I'm doing great, thanks for asking!
[1]: That's wonderful to hear.
[3]: Hey everyone, mind if I join the conversation?
[2]: Not at all, welcome!
Important Notes:
- Use
[1]:,[2]:,[3]:,[4]:for speaker labels - Maximum 4 speakers supported
- The system automatically detects the number of speakers from your text
- Each speaker can have an optional voice sample for cloning
- Size: ~5GB download
- Speed: Faster inference
- Quality: Good for single speaker
- Use Case: Quick prototyping, single voices
- Size: ~17GB download
- Speed: Slower inference but optimized
- Quality: Best available quality
- Use Case: Highest quality production, multi-speaker conversations
- Note: Latest official release from Microsoft
- Size: ~7GB download
- Speed: Balanced inference
- Quality: Good quality
- Use Case: Good quality production with less VRAM, multi-speaker conversations
- Note: Quantized by DevParker
Models are automatically downloaded on first use and cached in ComfyUI/models/vibevoice/.
use_sampling = False- Produces consistent, stable output
- Recommended for production use
use_sampling = True- More variation in output
- Uses temperature and top_p parameters
- Good for creative exploration
To clone a voice:
- Connect an audio node to the
voice_to_cloneinput (single speaker) - Or connect to
speaker1_voice,speaker2_voice, etc. (multi-speaker) - The model will attempt to match the voice characteristics
Requirements for voice samples:
- Clear audio with minimal background noise
- Minimum 3–10 seconds. Recommended at least 30 seconds for better quality
- Automatically resampled to 24kHz
Starting from version 1.4.0, VibeVoice ComfyUI supports custom LoRA (Low-Rank Adaptation) adapters for fine-tuning voice characteristics. This allows you to train and use specialized voice models while maintaining the base VibeVoice capabilities.
-
LoRA Directory Structure: Place your LoRA adapter folders in:
ComfyUI/models/vibevoice/loras/ComfyUI/ └── models/ └── vibevoice/ └── loras/ ├── my_custom_voice/ │ ├── adapter_config.json │ ├── adapter_model.safetensors │ └── diffusion_head/ (optional) ├── character_voice/ └── style_adaptation/ -
Required Files:
adapter_config.json: LoRA configurationadapter_model.safetensorsoradapter_model.bin: Model weights- Optional components:
diffusion_head/: Custom diffusion head weightsacoustic_connector/: Acoustic connector adaptationsemantic_connector/: Semantic connector adaptation
-
Add VibeVoice LoRA Node:
- Create a "VibeVoice LoRA" node in your workflow
- Select your LoRA from the dropdown menu
- Configure component settings and strength
-
Connect to Speaker Nodes:
- Connect the LoRA node's output to the
lorainput of speaker nodes - Both Single Speaker and Multiple Speakers nodes support LoRA
- Connect the LoRA node's output to the
-
LoRA Parameters:
- llm_strength: Controls the influence of the language model LoRA (0.0-2.0)
- Component toggles: Enable/disable specific LoRA components
- Select "None" to disable LoRA and use the base model
To create custom LoRA adapters for VibeVoice, use the official fine-tuning repository:
- Repository: VibeVoice Fine-tuning
- Features:
- Parameter-efficient fine-tuning
- Support for custom datasets
- Adjustable LoRA rank and scaling
- Optional diffusion head adaptation
- Voice Consistency: Use the same LoRA across all chunks for long texts
- Memory Management: LoRA adds minimal memory overhead (~100-500MB)
- Compatibility: LoRA adapters are compatible with all VibeVoice model variants
- Strength Tuning: Start with default strength (1.0) and adjust based on results
transformers==4.51.3. While our wrapper supports transformers>=4.51.3, LoRA functionality with newer versions of transformers is not guaranteed. If you experience issues with LoRA loading, consider using transformers==4.51.3 specifically:
pip install transformers==4.51.3LoRA implementation by @jpgallegoar (PR #127)
The Voice Speed Control feature allows you to influence the speaking rate of generated speech by adjusting the speed of the reference voice. This feature modifies the input voice sample before processing, causing the model to learn and reproduce the altered speech rate.
Available from version 1.5.0
The system applies time-stretching to the reference voice audio:
- Values < 1.0 slow down the reference voice, resulting in slower generated speech
- Values > 1.0 speed up the reference voice, resulting in faster generated speech
- The model learns from the modified voice characteristics and generates speech at a similar pace
- Parameter:
voice_speed_factor - Range: 0.8 to 1.2
- Default: 1.0 (normal speed)
- Step: 0.01 (1% increments)
- Optimal Range: 0.95 to 1.05 for natural-sounding results
- Slower Speech: Try 0.95 (5% slower) or 0.97 (3% slower)
- Faster Speech: Try 1.03 (3% faster) or 1.05 (5% faster)
- Best Results: Provide reference audio of at least 20 seconds for more accurate speed matching
- The effect works best with longer reference audio samples (20+ seconds recommended)
- Extreme values (< 0.9 or > 1.1) may produce unnatural-sounding speech
- In Multi Speaker mode, the speed adjustment applies to all speakers equally
- Synthetic voices (when no audio is provided) are not affected by this parameter
# Single Speaker
voice_speed_factor: 0.95 # Slightly slower, more deliberate speech
voice_speed_factor: 1.05 # Slightly faster, more energetic speech
# Multi Speaker
voice_speed_factor: 0.98 # All speakers talk 2% slower
voice_speed_factor: 1.02 # All speakers talk 2% faster
The VibeVoice wrapper includes a custom pause tag feature that allows you to insert silences between text segments. This is NOT a standard Microsoft VibeVoice feature - it's an original implementation of our wrapper to provide more control over speech pacing.
Available from version 1.3.0
You can use two types of pause tags in your text:
[pause]- Inserts a 1-second silence (default)[pause:ms]- Inserts a custom duration silence in milliseconds (e.g.,[pause:2000]for 2 seconds)
Welcome to our presentation. [pause] Today we'll explore artificial intelligence. [pause:500] Let's begin!
[1]: Hello everyone [pause] how are you doing today?
[2]: I'm doing great! [pause:500] Thanks for asking.
[1]: Wonderful to hear!
Note: The pause forces the text to be split into chunks. This may worsen the model's ability to understand the context. The model's context is represented ONLY by its own chunk.
This means:
- Text before a pause and text after a pause are processed separately
- The model cannot see across pause boundaries when generating speech
- This may affect prosody and intonation consistency
- This may affect prosody and intonation consistency
- The wrapper parses your text to find pause tags
- Text segments between pauses are processed independently
- Silence audio is generated for each pause duration
- All audio segments (speech and silence) are concatenated
- Use pauses at natural breaking points (end of sentences, paragraphs)
- Avoid pauses in the middle of phrases where context is important
- Test different pause durations to find what sounds most natural
-
Text Preparation:
- Use proper punctuation for natural pauses
- Break long texts into paragraphs
- For multi-speaker, ensure clear speaker transitions
- Use pause tags sparingly to maintain context continuity
-
Model Selection:
- Use 1.5B for quick single-speaker tasks (fastest, ~8GB VRAM)
- Use Large for best quality and multi-speaker (~16GB VRAM)
- Use Large-Quant-4Bit for good quality and low VRAM usage (~7GB VRAM)
-
Seed Management:
- Default seed (42) works well for most cases
- Save good seeds for consistent character voices
- Try random seeds if default doesn't work well
-
Performance:
- First run downloads models (5-17GB)
- Subsequent runs use cached models
- GPU recommended for faster inference
- Minimum: 8GB VRAM for VibeVoice-1.5B
- Recommended: 17GB+ VRAM for VibeVoice-Large
- RAM: 16GB+ system memory
- Python 3.8+
- PyTorch 2.0+
- CUDA 11.8+ (for GPU acceleration)
- Transformers 4.51.3+
- ComfyUI (latest version)
- Ensure you're using ComfyUI's Python environment
- Try manual installation if automatic fails
- Restart ComfyUI after installation
- If voices sound unstable, try deterministic mode
- For multi-speaker, ensure text has proper
[N]:format - Check that speaker numbers are sequential (1,2,3 not 1,3,5)
- Large model requires ~16GB VRAM
- Use 1.5B model for lower VRAM systems
- Models use bfloat16 precision for efficiency
Text: "Welcome to our presentation. Today we'll explore the fascinating world of artificial intelligence."
Model: [Select from available models]
cfg_scale: 1.3
use_sampling: False
[1]: Have you seen the new AI developments?
[2]: Yes, they're quite impressive!
[1]: I think voice synthesis has come a long way.
[2]: Absolutely, it sounds so natural now.
[1]: Welcome everyone to our meeting.
[2]: Thanks for having us!
[3]: Glad to be here.
[4]: Looking forward to the discussion.
[1]: Let's begin with the agenda.
| Model | VRAM Usage | Context Length | Max Audio Duration |
|---|---|---|---|
| VibeVoice-1.5B | ~8GB | 64K tokens | ~90 minutes |
| VibeVoice-Large | ~17GB | 32K tokens | ~45 minutes |
| VibeVoice-Large-Quant-4Bit | ~7GB | 32K tokens | ~45 minutes |
- Maximum 4 speakers in multi-speaker mode
- Works best with English and Chinese text
- Some seeds may produce unstable output
- Background music generation cannot be directly controlled
This ComfyUI wrapper is released under the MIT License. See LICENSE file for details.
Note: The VibeVoice model itself is subject to Microsoft's licensing terms:
- VibeVoice is for research purposes only
- Check Microsoft's VibeVoice repository for full model license details
- Original VibeVoice Repository - Official Microsoft VibeVoice repository (currently unavailable)
- VibeVoice Model: Microsoft Research
- ComfyUI Integration: Fabio Sarracino
- Base Model: Built on Qwen2.5 architecture
For issues or questions:
- Check the troubleshooting section
- Review ComfyUI logs for error messages
- Ensure VibeVoice is properly installed
- Open an issue with detailed error information
Contributions welcome! Please:
- Test changes thoroughly
- Follow existing code style
- Update documentation as needed
- Submit pull requests with clear descriptions
- Improved integration by removing HuggingFace unnecessary settings
- Major Change: Removed automatic model downloading from HuggingFace
- Models must now be manually downloaded and placed in
ComfyUI/models/vibevoice/ - Dynamic model dropdown that scans available models on each browser refresh
- Support for custom folder names and HuggingFace cache structure
- Automatic detection of quantized models from config files
- Better user control over model management
- Eliminates authentication issues with private HuggingFace repos
- Models must now be manually downloaded and placed in
- Improved Logging System:
- Optimized logging to reduce console clutter
- Cleaner output for better user experience
- Added Voice Speed Control feature for adjusting speech rate
- New
voice_speed_factorparameter in both Single and Multi Speaker nodes - Time-stretching applied to reference audio to influence output speech rate
- Range: 0.8 to 1.2 with 0.01 step increments
- Recommended range: 0.95 to 1.05 for natural results
- Best results with 20+ seconds of reference audio
- New
- Improved LoRA system with better logging and compatibility checks
- Added model compatibility detection to prevent mismatched LoRA loading
- Enhanced debug logging for LoRA component loading process
- Automatic detection and clear error messages for incompatible model-LoRA combinations
- Prevents loading errors when using quantized models with standard LoRAs
- Minor optimizations to LoRA weight loading process
- Bug Fixing
- Fixed HuggingFace authentication error when loading locally cached models
- Resolved 401 authorization errors for already downloaded models
- Node now correctly uses local model snapshots without requiring HuggingFace API authentication
- Prevents unnecessary API calls when models exist in
ComfyUI/models/vibevoice/
- Added LoRA (Low-Rank Adaptation) support for fine-tuned models
- New "VibeVoice LoRA" node for configuring custom voice adaptations
- Support for language model, diffusion head, and connector adaptations
- Dropdown menu for easy LoRA selection from
ComfyUI/models/vibevoice/loras/ - Adjustable LoRA strength and component toggles
- Compatible with both Single and Multiple Speaker nodes
- Minimal memory overhead (~100-500MB per LoRA)
- Credits: Implementation by @jpgallegoar
- Added custom pause tag support for speech pacing control
- New
[pause]tag for 1-second silence (default) - New
[pause:ms]tag for custom duration in milliseconds (e.g.,[pause:2000]for 2 seconds) - Works with both Single Speaker and Multiple Speakers nodes
- Automatically splits text at pause points while maintaining voice consistency
- Note: This is a wrapper feature, not part of Microsoft's VibeVoice
- New
- Bug Fixing
- Added automatic text chunking for long texts in Single Speaker node
- Single Speaker node now automatically splits texts longer than 250 words to prevent audio acceleration issues
- New optional parameter
max_words_per_chunk(range: 100-500 words, default: 250) - Maintains consistent voice characteristics across all chunks using the same seed
- Seamlessly concatenates audio chunks for smooth, natural output
- Added SageAttention support for inference speedup
- New attention option "sage" using quantized attention (INT8/FP8) for faster generation
- Requirements: NVIDIA GPU with CUDA and sageattention library installation
- Added 4-bit quantized model support
- New model in menu:
VibeVoice-Large-Quant-4Bitusing ~7GB VRAM instead of ~17GB - Requirements: NVIDIA GPU with CUDA and bitsandbytes library installed
- New model in menu:
- Bug Fixing
- MPS Support for Apple Silicon:
- Added GPU acceleration support for Mac with Apple Silicon (M1/M2/M3)
- Automatically detects and uses MPS backend when available, providing significant performance improvements over CPU
- Universal Transformers Compatibility:
- Implemented adaptive system that automatically adjusts to different transformers versions
- Guaranteed compatibility from v4.51.3 onwards
- Auto-detects and adapts to API changes between versions
- Updated the URL for downloading the VibeVoice-Large model
- Removed VibeVoice-Large-Preview deprecated model
- Embedded VibeVoice code directly into the wrapper
- Added vvembed folder containing the complete VibeVoice code (MIT licensed)
- No longer requires external VibeVoice installation
- Ensures continued functionality for all users
- BFloat16 Compatibility Fix
- Fixed tensor type compatibility issues with audio processing nodes
- Input audio tensors are now converted from BFloat16 to Float32 for numpy compatibility
- Output audio tensors are explicitly converted to Float32 to ensure compatibility with downstream nodes
- Resolves "Got unsupported ScalarType BFloat16" errors when using voice cloning or saving audio
- Added interruption handler to detect user's cancel request
- Bug fixing
- Fixed a bug that prevented VibeVoice nodes from receiving audio directly from another VibeVoice node
- Added support for Microsoft's official VibeVoice-Large model (stable release)
- Improved tokenizer dependency handling
- Added
attention_typeparameter to both Single Speaker and Multi Speaker nodes for performance optimization- auto (default): Automatic selection of best implementation
- eager: Standard implementation without optimizations
- sdpa: PyTorch's optimized Scaled Dot Product Attention
- flash_attention_2: Flash Attention 2 for maximum performance (requires compatible GPU)
- Added
diffusion_stepsparameter to control generation quality vs speed trade-off- Default: 20 (VibeVoice default)
- Higher values: Better quality, longer generation time
- Lower values: Faster generation, potentially lower quality
- Added
free_memory_after_generatetoggle to both Single Speaker and Multi Speaker nodes - New dedicated "Free Memory Node" for manual memory management in workflows
- Improved VRAM/RAM usage optimization
- Enhanced stability for long generation sessions
- Users can now choose between automatic or manual memory management
- Fixed issue with line breaks in speaker text (both single and multi-speaker nodes)
- Line breaks within individual speaker text are now automatically removed before generation
- Improved text formatting handling for all generation modes
- Initial release
- Single speaker node with voice cloning
- Multi-speaker node with automatic speaker detection
- Text file loading from ComfyUI directories
- Deterministic and sampling generation modes
- Support for VibeVoice 1.5B and Large models