fix(deps): update dependency vllm to ^0.11.0 [security] #280
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| datasource | package | from | to | | ---------- | ------- | ----- | ------ | | pypi | vllm | 0.5.5 | 0.11.0 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
This PR contains the following updates:
^0.5.0->^0.11.0GitHub Vulnerability Alerts
CVE-2025-24357
Description
The vllm/model_executor/weight_utils.py implements hf_model_weights_iterator to load the model checkpoint, which is downloaded from huggingface. It use torch.load function and weights_only parameter is default value False. There is a security warning on https://pytorch.org/docs/stable/generated/torch.load.html, when torch.load load a malicious pickle data it will execute arbitrary code during unpickling.
Impact
This vulnerability can be exploited to execute arbitrary codes and OS commands in the victim machine who fetch the pretrained repo remotely.
Note that most models now use the safetensors format, which is not vulnerable to this issue.
References
CVE-2025-25183
Summary
Maliciously constructed prompts can lead to hash collisions, resulting in prefix cache reuse, which can interfere with subsequent responses and cause unintended behavior.
Details
vLLM's prefix caching makes use of Python's built-in hash() function. As of Python 3.12, the behavior of hash(None) has changed to be a predictable constant value. This makes it more feasible that someone could try exploit hash collisions.
Impact
The impact of a collision would be using cache that was generated using different content. Given knowledge of prompts in use and predictable hashing behavior, someone could intentionally populate the cache using a prompt known to collide with another prompt in use.
Solution
We address this problem by initializing hashes in vllm with a value that is no longer constant and predictable. It will be different each time vllm runs. This restores behavior we got in Python versions prior to 3.12.
Using a hashing algorithm that is less prone to collision (like sha256, for example) would be the best way to avoid the possibility of a collision. However, it would have an impact to both performance and memory footprint. Hash collisions may still occur, though they are no longer straight forward to predict.
To give an idea of the likelihood of a collision, for randomly generated hash values (assuming the hash generation built into Python is uniformly distributed), with a cache capacity of 50,000 messages and an average prompt length of 300, a collision will occur on average once every 1 trillion requests.
References
CVE-2025-29770
Impact
The outlines library is one of the backends used by vLLM to support structured output (a.k.a. guided decoding). Outlines provides an optional cache for its compiled grammars on the local filesystem. This cache has been on by default in vLLM. Outlines is also available by default through the OpenAI compatible API server.
The affected code in vLLM is vllm/model_executor/guided_decoding/outlines_logits_processors.py, which unconditionally uses the cache from outlines. vLLM should have this off by default and allow administrators to opt-in due to the potential for abuse.
A malicious user can send a stream of very short decoding requests with unique schemas, resulting in an addition to the cache for each request. This can result in a Denial of Service if the filesystem runs out of space.
Note that even if vLLM was configured to use a different backend by default, it is still possible to choose outlines on a per-request basis using the
guided_decoding_backendkey of theextra_bodyfield of the request.This issue applies to the V0 engine only. The V1 engine is not affected.
Patches
The fix is to disable this cache by default since it does not provide an option to limit its size. If you want to use this cache anyway, you may set the
VLLM_V0_USE_OUTLINES_CACHEenvironment variable to1.Workarounds
There is no way to workaround this issue in existing versions of vLLM other than preventing untrusted access to the OpenAI compatible API server.
References
GHSA-ggpf-24jw-3fcw
Description
GHSA-rh4j-5rhw-hr54 reported a vulnerability where loading a malicious model could result in code execution on the vllm host. The fix applied to specify
weights_only=Trueto calls totorch.load()did not solve the problem prior to PyTorch 2.6.0.PyTorch has issued a new CVE about this problem: GHSA-53q9-r3pm-6pq6
This means that versions of vLLM using PyTorch before 2.6.0 are vulnerable to this problem.
Background Knowledge
When users install VLLM according to the official manual

But the version of PyTorch is specified in the requirements. txt file
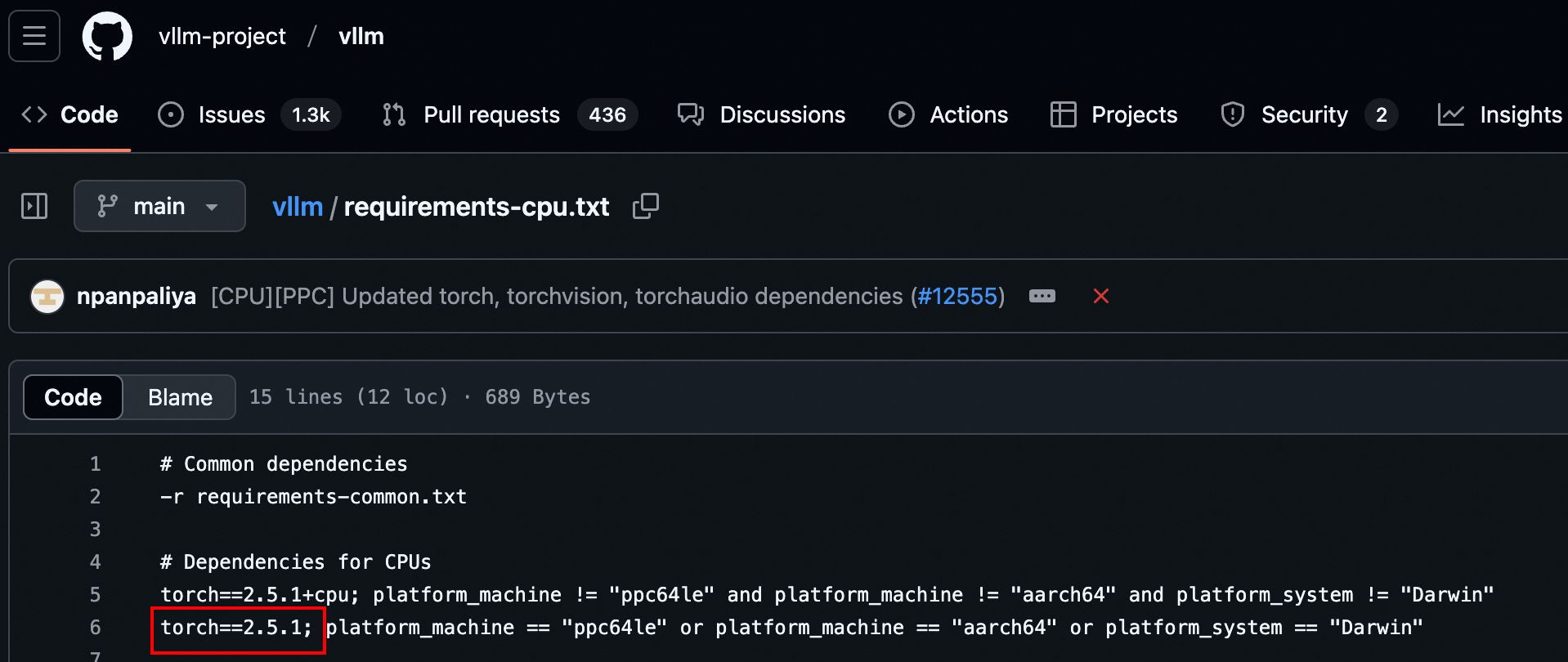
So by default when the user install VLLM, it will install the PyTorch with version 2.5.1

In CVE-2025-24357, weights_only=True was used for patching, but we know this is not secure.
Because we found that using Weights_only=True in pyTorch before 2.5.1 was unsafe
Here, we use this interface to prove that it is not safe.

Fix
update PyTorch version to 2.6.0
Credit
This vulnerability was found By Ji'an Zhou and Li'shuo Song
CVE-2025-30202
Impact
In a multi-node vLLM deployment, vLLM uses ZeroMQ for some multi-node communication purposes. The primary vLLM host opens an
XPUBZeroMQ socket and binds it to ALL interfaces. While the socket is always opened for a multi-node deployment, it is only used when doing tensor parallelism across multiple hosts.Any client with network access to this host can connect to this
XPUBsocket unless its port is blocked by a firewall. Once connected, these arbitrary clients will receive all of the same data broadcasted to all of the secondary vLLM hosts. This data is internal vLLM state information that is not useful to an attacker.By potentially connecting to this socket many times and not reading data published to them, an attacker can also cause a denial of service by slowing down or potentially blocking the publisher.
Detailed Analysis
The
XPUBsocket in question is created here:https://github.com/vllm-project/vllm/blob/c21b99b91241409c2fdf9f3f8c542e8748b317be/vllm/distributed/device_communicators/shm_broadcast.py#L236-L237
Data is published over this socket via
MessageQueue.enqueue()which is called byMessageQueue.broadcast_object():https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/device_communicators/shm_broadcast.py#L452-L453
https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/device_communicators/shm_broadcast.py#L475-L478
The
MessageQueue.broadcast_object()method is called by theGroupCoordinator.broadcast_object()method inparallel_state.py:https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/parallel_state.py#L364-L366
The broadcast over ZeroMQ is only done if the
GroupCoordinatorwas created withuse_message_queue_broadcasterset toTrue:https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/parallel_state.py#L216-L219
The only case where
GroupCoordinatoris created withuse_message_queue_broadcasteris the coordinator for the tensor parallelism group:https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/parallel_state.py#L931-L936
To determine what data is broadcasted to the tensor parallism group, we must continue tracing.
GroupCoordinator.broadcast_object()is called byGroupCoordinator.broadcoast_tensor_dict():https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/parallel_state.py#L489
which is called by
broadcast_tensor_dict()incommunication_op.py:https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/communication_op.py#L29-L34
If we look at
_get_driver_input_and_broadcast()in the V0worker_base.py, we'll see how this tensor dict is formed:https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/worker/worker_base.py#L332-L352
but the data actually sent over ZeroMQ is the
metadata_listportion that is split from thistensor_dict. The tensor parts are sent viatorch.distributedand only metadata about those tensors is sent via ZeroMQ.https://github.com/vllm-project/vllm/blob/54a66e5fee4a1ea62f1e4c79a078b20668e408c6/vllm/distributed/parallel_state.py#L61-L83
Patches
Workarounds
Prior to the fix, your options include:
XPUBsocket. Note that port used is random.References
CVE-2025-46570
This issue arises from the prefix caching mechanism, which may expose the system to a timing side-channel attack.
Description
When a new prompt is processed, if the PageAttention mechanism finds a matching prefix chunk, the prefill process speeds up, which is reflected in the TTFT (Time to First Token). Our tests revealed that the timing differences caused by matching chunks are significant enough to be recognized and exploited.
For instance, if the victim has submitted a sensitive prompt or if a valuable system prompt has been cached, an attacker sharing the same backend could attempt to guess the victim's input. By measuring the TTFT based on prefix matches, the attacker could verify if their guess is correct, leading to potential leakage of private information.
Unlike token-by-token sharing mechanisms, vLLM’s chunk-based approach (PageAttention) processes tokens in larger units (chunks). In our tests, with chunk_size=2, the timing differences became noticeable enough to allow attackers to infer whether portions of their input match the victim's prompt at the chunk level.
Environment
Configuration: We launched vLLM using the default settings and adjusted chunk_size=2 to evaluate the TTFT.
Leakage
We conducted our tests using LLaMA2-70B-GPTQ on a single device. We analyzed the timing differences when prompts shared prefixes of 2 chunks, and plotted the corresponding ROC curves. Our results suggest that timing differences can be reliably used to distinguish prefix matches, demonstrating a potential side-channel vulnerability.

Results
In our experiment, we analyzed the response time differences between cache hits and misses in vLLM's PageAttention mechanism. Using ROC curve analysis to assess the distinguishability of these timing differences, we observed the following results:
Fixes
CVE-2025-48956
Summary
A Denial of Service (DoS) vulnerability can be triggered by sending a single HTTP GET request with an extremely large header to an HTTP endpoint. This results in server memory exhaustion, potentially leading to a crash or unresponsiveness. The attack does not require authentication, making it exploitable by any remote user.
Details
The vulnerability leverages the abuse of HTTP headers. By setting a header such as
X-Forwarded-Forto a very large value like("A" * 5_800_000_000), the server's HTTP parser or application logic may attempt to load the entire request into memory, overwhelming system resources.Impact
What kind of vulnerability is it? Who is impacted?
Type of vulnerability: Denial of Service (DoS)
Resolution
Upgrade to a version of vLLM that includes appropriate HTTP limits by deafult, or use a proxy in front of vLLM which provides protection against this issue.
CVE-2025-59425
Summary
The API key support in vLLM performed validation using a method that was vulnerable to a timing attack. This could potentially allow an attacker to discover a valid API key using an approach more efficient than brute force.
Details
https://github.com/vllm-project/vllm/blob/4b946d693e0af15740e9ca9c0e059d5f333b1083/vllm/entrypoints/openai/api_server.py#L1270-L1274
API key validation used a string comparison that will take longer the more characters the provided API key gets correct. Data analysis across many attempts can allow an attacker to determine when it finds the next correct character in the key sequence.
Impact
Deployments relying on vLLM's built-in API key validation are vulnerable to authentication bypass using this technique.
CVE-2025-61620
Summary
A resource-exhaustion (denial-of-service) vulnerability exists in multiple endpoints of the OpenAI-Compatible Server due to the ability to specify Jinja templates via the
chat_templateandchat_template_kwargsparameters. If an attacker can supply these parameters to the API, they can cause a service outage by exhausting CPU and/or memory resources.Details
When using an LLM as a chat model, the conversation history must be rendered into a text input for the model. In
hf/transformer, this rendering is performed using a Jinja template. The OpenAI-Compatible Server launched by vllm serve exposes achat_templateparameter that lets users specify that template. In addition, the server accepts achat_template_kwargsparameter to pass extra keyword arguments to the rendering function.Because Jinja templates support programming-language-like constructs (loops, nested iterations, etc.), a crafted template can consume extremely large amounts of CPU and memory and thereby trigger a denial-of-service condition.
Importantly, simply forbidding the
chat_templateparameter does not fully mitigate the issue. The implementation constructs a dictionary of keyword arguments forapply_hf_chat_templateand then updates that dictionary with the user-suppliedchat_template_kwargsviadict.update. Sincedict.updatecan overwrite existing keys, an attacker can place achat_templatekey insidechat_template_kwargsto replace the template that will be used byapply_hf_chat_template.Impact
If an OpenAI-Compatible Server exposes endpoints that accept
chat_templateorchat_template_kwargsfrom untrusted clients, an attacker can submit a malicious Jinja template (directly or by overridingchat_templateinsidechat_template_kwargs) that consumes excessive CPU and/or memory. This can result in a resource-exhaustion denial-of-service that renders the server unresponsive to legitimate requests.Fixes
CVE-2025-6242
Summary
A Server-Side Request Forgery (SSRF) vulnerability exists in the
MediaConnectorclass within the vLLM project's multimodal feature set. Theload_from_urlandload_from_url_asyncmethods fetch and process media from user-provided URLs without adequate restrictions on the target hosts. This allows an attacker to coerce the vLLM server into making arbitrary requests to internal network resources.This vulnerability is particularly critical in containerized environments like
llm-d, where a compromised vLLM pod could be used to scan the internal network, interact with other pods, and potentially cause denial of service or access sensitive data. For example, an attacker could make the vLLM pod send malicious requests to an internalllm-dmanagement endpoint, leading to system instability by falsely reporting metrics like the KV cache state.Vulnerability Details
The core of the vulnerability lies in the
MediaConnector.load_from_urlmethod and its asynchronous counterpart. These methods accept a URL string to fetch media content (images, audio, video).https://github.com/vllm-project/vllm/blob/119f683949dfed10df769fe63b2676d7f1eb644e/vllm/multimodal/utils.py#L97-L113
The function directly processes URLs with
http,https, andfileschemes. An attacker can supply a URL pointing to an internal IP address or alocalhostendpoint. The vLLM server will then initiate a connection to this internal resource.{"image_url": "http://127.0.0.1:8080/internal_api"}. The vLLM server will send a GET request to this internal endpoint._load_file_urlmethod attempts to restrict file access to a subdirectory defined by--allowed-local-media-path. While this is a good security measure for local file access, it does not prevent network-based SSRF attacks.Impact in
llm-dEnvironmentsThe risk is significantly amplified in orchestrated environments such as
llm-d, where multiple pods communicate over an internal network.Denial of Service (DoS): An attacker could target internal management endpoints of other services within the
llm-dcluster. For instance, if a monitoring or metrics service is exposed internally, an attacker could send malformed requests to it. A specific example is an attacker causing the vLLM pod to call an internal API that reports a false KV cache utilization, potentially triggering incorrect scaling decisions or even a system shutdown.Internal Network Reconnaissance: Attackers can use the vulnerability to scan the internal network for open ports and services by providing URLs like
http://10.0.0.X:PORTand observing the server's response time or error messages.Interaction with Internal Services: Any unsecured internal service becomes a potential target. This could include databases, internal APIs, or other model pods that might not have robust authentication, as they are not expected to be directly exposed.
Delegating this security responsibility to an upper-level orchestrator like
llm-dis problematic. The orchestrator cannot easily distinguish between legitimate requests initiated by the vLLM engine for its own purposes and malicious requests originating from user input, thus complicating traffic filtering rules and increasing management overhead.Proposed Mitigation
To address this vulnerability, it is essential to restrict the URLs that the
MediaConnectorcan access. The principle of least privilege should be applied.It is recommend to implement a configurable allowlist or denylist for domains and IP addresses.
Allowlist: The most secure approach is to allow connections only to a predefined list of trusted domains. This could be configured via a command-line argument, such as
--allowed-media-domains. By default, this list could be empty, forcing administrators to explicitly enable external media fetching.Denylist: Alternatively, a denylist could block access to private IP address ranges (
127.0.0.1,10.0.0.0/8,172.16.0.0/12,192.168.0.0/16) and other sensitive domains.A check should be added at the beginning of the
load_from_urlmethods to validate the parsed hostname against this list before any connection is made.Example Implementation Idea:
By integrating this control directly into vLLM, empower administrators to enforce security policies at the source, creating a more secure deployment by default and reducing the burden on higher-level infrastructure management.
Release Notes
vllm-project/vllm (vllm)
v0.11.0Compare Source
Highlights
This release features 538 commits, 207 contributors (65 new contributors)!
Note: In v0.11.0 (and v0.10.2),
--async-schedulingwill produce gibberish output in some cases such as preemption and others. This functionality is correct in v0.10.1. We are actively fixing it for the next version.Model Support
Engine Core
Hardware & Performance
Large Scale Serving & Performance
Quantization
API & Frontend
Security
Dependencies
xm.mark_stepin favor oftorch_xla.sync(#25254).V0 Deprecation
What's Changed
cpu_attn.py:_run_sdpa_forwardfor better memory access by @ignaciosica in #24701--enable-log-outputsdoes not match the documentation by @kebe7jun in #24626_validate_and_reshape_mm_tensorby @lgeiger in #24742supports_kwby @lgeiger in #24773s3_utilstype hints withBaseClientby @Zerohertz in #24825stopin reasoning content by @gaocegege in #14550kv_output_aggregatorsupport heterogeneous by @LCAIZJ in #23917MultiModalConfigfromconfig/__init__.pytoconfig/multimodal.pyby @hmellor in #24659Configuration
📅 Schedule: Branch creation - "" (UTC), Automerge - At any time (no schedule defined).
🚦 Automerge: Enabled.
♻ Rebasing: Whenever PR becomes conflicted, or you tick the rebase/retry checkbox.
🔕 Ignore: Close this PR and you won't be reminded about this update again.
This PR has been generated by Renovate Bot.