Perform mvcc read validation in parallel #489
Conversation
11de597 to
5547b41
Compare
| wg sync.WaitGroup | ||
| } | ||
|
|
||
| func (v *dataTxValidator) parallelReadMvccValidation( |
There was a problem hiding this comment.
Simplicity of code flow is very important for a longer term code maintenance. Here, the flow looks complicated due to go-routine dependencies. Why not make first set of goroutines finish before starting the second. Are there significant performance between these two flows?
There was a problem hiding this comment.
The first set of goroutines are strictly IO-bounded and the seconds are strictly compute-bounded.
I believe that a good portion of the benefit here comes from pipelining IO and compute-bounded tasks to utilize both the storage and CPU in parallel, rather than one after the other.
There was a problem hiding this comment.
Which part in the second set of goroutine is CPU intensive? If we are verifying signatures, I would agree but we are doing simple checks.
There was a problem hiding this comment.
It is not intensive, but it is CPU bound. A single version comparison might not be much, but we may have 1K to 1M comparisons. All of them together are nonnegligible, but hiding them by pipelining them with the IO-bound tasks reduces their apparent latency to zero.
There was a problem hiding this comment.
If you feel strongly about using this flow, go ahead. I will anyway share my view.
When we use cache for the read (when the client reads), there is a high possibility that the read content might be already available in the cache and disk reads may not be needed. Hence, it may not be a pure IO bounded. Further, active goroutines are dependent on the number of vCPUs. If we are taking about 1M goroutine, I doubt the typical server to handle that many number of goroutines and many might be waiting for the CPU thread. For every read and every version comparison, we are using a goroutine. Also, there is interdependencies between goroutines. Maybe I am wrong but it looks to me like over optimisation.
There was a problem hiding this comment.
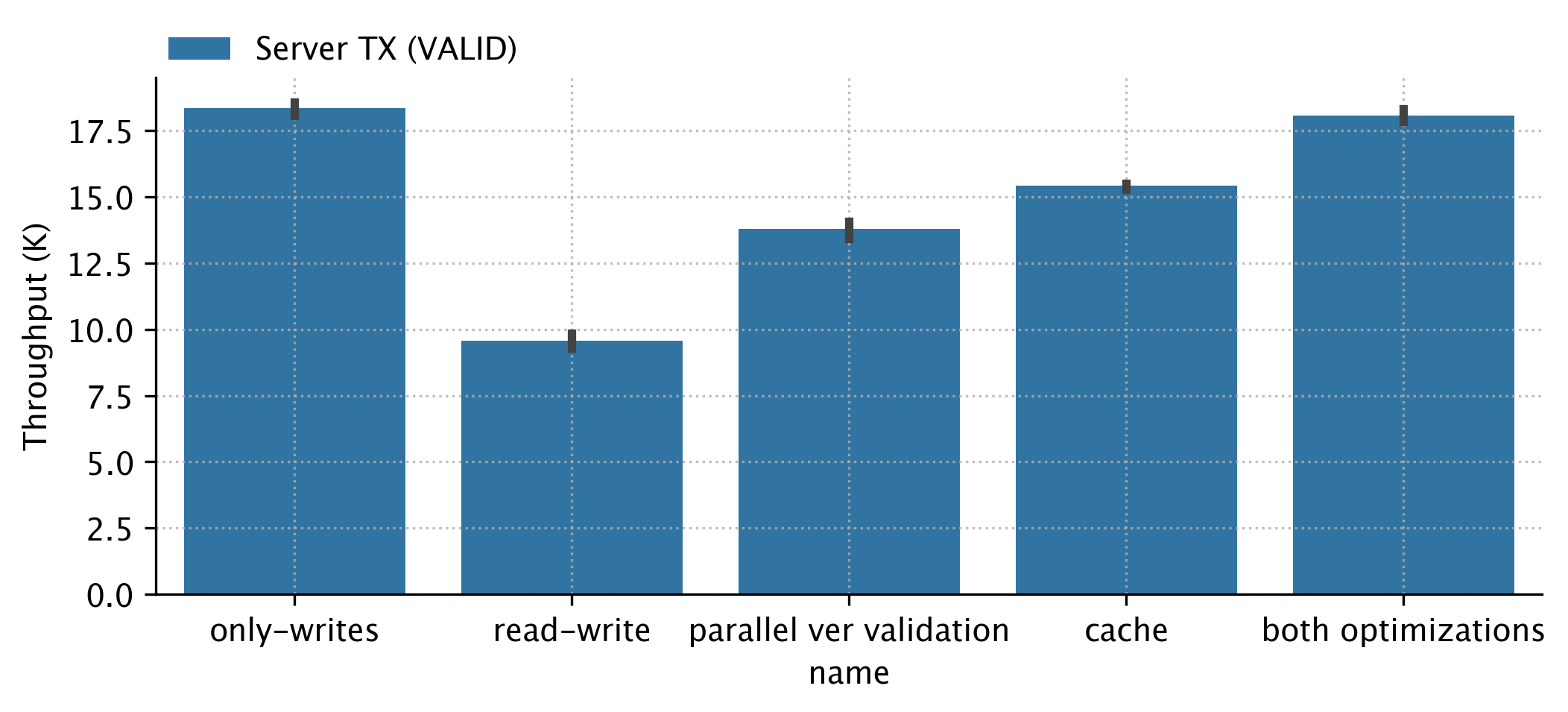
This improvement alone yielded a 25%-50% read-write-TXs throughput (TPS) increase.
Even if the pipelining amount to 10% of that increase, that would be a ±5% increase in TPS.
Let's postpone this discussion until after we'll add all the metrics to the main branch, then we could compare both flows.
There was a problem hiding this comment.
Okay. I will push a PR where version check for each tx is executed in parallel but no parallelism within a single transaction. This would simplify the code too and cache at the world state would anyway help with duplicate reads. In the end to end performance, my hypothesis is that this flow would be sufficient and simple enough. Let's check.
2cea3fb to
d02a98f
Compare
Signed-off-by: Liran Funaro <[email protected]>
Signed-off-by: Liran Funaro <[email protected]>
d02a98f to
424b7fc
Compare
The current implementation goes over each read operation- one by one- and validates if it was already written in this block and if the read version matches the current version.
The current design avoids redundant reading of keys' versions by checking first if previous pending operations overwrote this key. But this enforces a sequential implementation.
Instead, this PR takes an eager, optimistic approach.
We assume that conflicts are rare, so we eagerly read all keys' versions in parallel and check if the version matches.
Then, if all is OK, we continue to check the operations one by one to see if one operation invalidates another.
This removes the bottleneck caused by the expensive version read operation.
Signed-off-by: Liran Funaro [email protected]